As part of continuing education and the personal need to validate that my skills are polished, I routinely enjoy working on Digital Forensics and Incident Response challenges. I plan to start adding additional challenges to my blog going forward.
Recently, I caught wind of the Digital Forensics and Incident Response Monterey Network Forensics Challenge. SANS does a good job at creating these challenges and make the publicly available and free. This particular network forensics challenge consisted of 6 questions that required the analysis of the following data types:raw log data, flow data, and network traces. Besides having been really busy at work and at home lately, I decided to create a goal of making this challenge as close to a real life experience as possible. So I decided to get to the answers, however that may be, as quickly and efficiently as possible, somewhat simulating how incidents may transpond while on the job. On a personal note, I completed all 6 questions in less than 2 hours (minus the bonus question).
Question 1
Difficulty: Easy
Evidence: SWT-syslog_messages
Question: At what time (UTC, including year) did the portscanning activity from IP address 123.150.207.231 start?
Based off of the data provided in the question, what I did to identify when the port scanning started was to simply identify the first packet that 123.150.207.231 sent.
Based off of the data provided in the question, what I did to identify when the port scanning started was to simply identify the first packet that 123.150.207.231 sent.
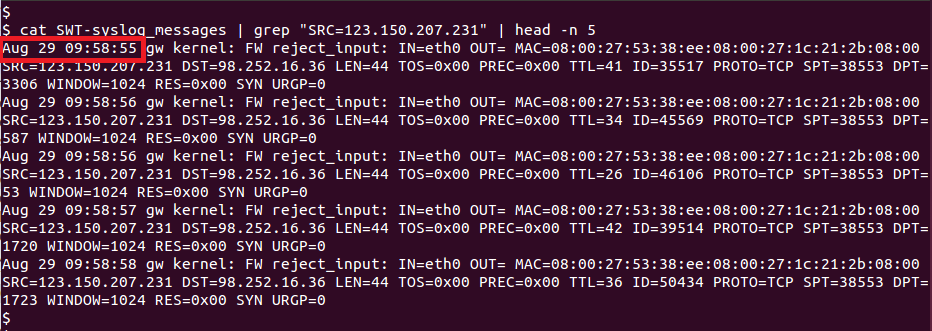

Answer: 13:58:55 UTC, 2013 (09:58:55 ET, 2013)
Question 2
Difficulty: Easy
Difficulty: Easy
Evidence: nitroba.pcap
Question: What IP addresses were used by the system claiming the MAC Address 00:1f:f3:5a:77:9b?
The answer was simple to obtain, assuming you understand the basics of ARP. I'm a big fan of tshark, so I used tshark to obtain all of the IPs that this MAC address claimed in the log data provided.
The answer was simple to obtain, assuming you understand the basics of ARP. I'm a big fan of tshark, so I used tshark to obtain all of the IPs that this MAC address claimed in the log data provided.

Question 3
Difficulty: Medium
Difficulty: Medium
Evidence: ftp-example.pcap
Question: What IP (source and destination) and TCP ports (source and destination) are used to transfer the "scenery-backgrounds-6.0.0-1.el6.noarch.rpm" file?
To obtain the source and destination IP’s and ports that were involved in transferring the file "scenery-backgrounds-6.0.0-1.el6.noarch.rpm", a very simple and quick filter showed the relevant data we were looking for.
To obtain the source and destination IP’s and ports that were involved in transferring the file "scenery-backgrounds-6.0.0-1.el6.noarch.rpm", a very simple and quick filter showed the relevant data we were looking for.

Answer: Data is transferred from 149.20.20.135:30472 to 192.168.75.29:51851
Question 4
Difficult: Medium
Difficult: Medium
Evidence: nfcapd.201405230000 (requires nfdump v1.6.12. Note that nfcapd.201405230000.txt is the same data in nfdump's "long" output format.)
Question: How many IP addresses attempted to connect to destination IP address 63.141.241.10 on the default SSH port?
I utilized a few Linux utilities to extract the total count of IPs that attempted connections to 63.141.241.10 on destination port 22 (SSH). I made the decision not to extract IPs that made full connections (think TCP 3-way handshake). Instead, IPs were identified by having sent any packets to the destination IP, regardless of what flags were set and what order they were received. On a personal note, I was excited to see flow data used in this challenge. I can’t express enough how valuable flow data is to the incident responder and network security analyst.
I utilized a few Linux utilities to extract the total count of IPs that attempted connections to 63.141.241.10 on destination port 22 (SSH). I made the decision not to extract IPs that made full connections (think TCP 3-way handshake). Instead, IPs were identified by having sent any packets to the destination IP, regardless of what flags were set and what order they were received. On a personal note, I was excited to see flow data used in this challenge. I can’t express enough how valuable flow data is to the incident responder and network security analyst.
An explanation of the below command is as follows: awk is used to identify the lines that match the destination IP/port, removes some unneeded data in that line, prints out the scanning IPs, removes duplicate IPs, and then prints out the count of unique IPs that sent at least one recorded packet to the destination/port combo.

Answer: 49
Question 5
Difficulty: Hard
Difficulty: Hard
Evidence: stark-20120403-full-smb_smb2.pcap
Question: What is the byte size for the file named "Researched Sub-Atomic Particles.xlsx"?
This first screenshot shows the FIND_FIRST2 subcommand within the smb protocol. This command is used to search for files in a directory. Keep in mind that this subcommand does not mean a file was actually transferred. I used it to identify the file size of the file "Researched Sub-Atomic Particles.xlsx" from the file listing.
This first screenshot shows the FIND_FIRST2 subcommand within the smb protocol. This command is used to search for files in a directory. Keep in mind that this subcommand does not mean a file was actually transferred. I used it to identify the file size of the file "Researched Sub-Atomic Particles.xlsx" from the file listing.


Question 6
Difficulty: Very Hard
Difficulty: Very Hard
Evidence: snort.log.1340504390.pcap
Question: The traffic in this Snort IDS pcap log contains traffic that is suspected to be a malware beaconing. Identify the substring and offset for a common substring that would support a unique Indicator Of Compromise for this activity.
This one was really fun.
This one was really fun.
To start off, I randomly pulled a few streams out of this packet capture to see what I was dealing with. I initially noticed the data section of each stream had some similarities, including the same data segment size (32 bytes) for each. The below tshark command was used to extract the raw data out of each stream.


A snort signature could easily be created on this unique substring (and offset) and should provide pretty high fidelity.
As an additional challenge to myself (after I initially completed this challenge), I wrote a script that performs pattern matching of raw data from streams that attempts to identify patterns with actually providing a pattern to match on. I wrote it based solely off of this data and it works for this data. I haven't been able to thoroughly test it on enough data sets to feel comfortable with sharing just yet.
Answer: ULQENP2 (ASCII) 554c51454e5032 (hex) and bytes 5 through 11
Bonus Question: Identify the meaning of the bytes that precede the substring above.

0x4fe6c274 (hex) → 1340523124 (decimal) → Sun, 24 Jun 2012 07:32:04 GMT(UNIX timestamp)










